Introduction – What we’ll create
In this tutorial, we shall see how to share a layer across two services in AWS Lambda. We will use the Python runtime, and share the PythonRequirementsLambdaLayer across two services.
Listed below is the structure of this tutorial:
- Prerequisites
- Deploying the first service with PythonRequirementsLambdaLayer with global access
- Deploy the second service, which uses the layer from the first service
- Test out a function in the second service
- Why share layers across services?
Alright, let’s begin!
Prerequisites
It is assumed that you are familiar with AWS Lambda and familiar with layers. If not, you can check out this article to know more about AWS Lambda Layers. Familiarity with python and the python requirements layer will help, although it is not a strict requirement.
Deploying the first service with PythonRequirementsLambdaLayer with global access
We’ll create a very simple service, and add to it the Python Requirements layer. We will create a token ‘Hello World’ function along with this service.
The code (serverlesss+handler) for this first service, and the next service that we create, can be found on GitHub.
The serverless.yml file looks like this:
service: service-with-requirements-layer
provider:
name: aws
runtime: python3.6
lambdaHashingVersion: 20201221
region: us-west-2
functions:
hello:
handler: handler.hello
layers:
- {Ref: PythonRequirementsLambdaLayer}
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
layer:
description: Python requirements lambda layer
allowedAccounts:
- '*'Note that we are using the serverless-python-requirements plugin for bundling all the requirements. Also, note that we are using docker to make the package OS-independent. Why? Libraries like NumPy and Pandas require the compilation of C-extensions and if you use a Windows or a Mac machine, then the libraries compiled locally on these machines will not work in the Lambda environment, which is Linux-based. Docker solves this problem. You can read more about the usage of docker in serverless here.
Note that within the custom package, we section, we have told serverless to add the python requirements in a layer, and set its access level to global (using allowedAccounts), meaning anyone can access that layer. You can also restrict the access to specific accounts. See the serverless layers documentation.
The serverless-python-requirements plugin packages the libraries listed in requirements.txt. Our requirements.txt looks like the following:
numpy==1.14.5
pandas==0.25.0
Note that our handler function, whose code is given below, uses none of these libraries. However, the next service that we deploy will use some of these dependencies.
import json
def hello(event, context):
body = {
"message": "Go Serverless v1.0! Your function executed successfully!",
"input": event
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return responseOnce you deploy this to AWS, you should be able to see that it has a layer.
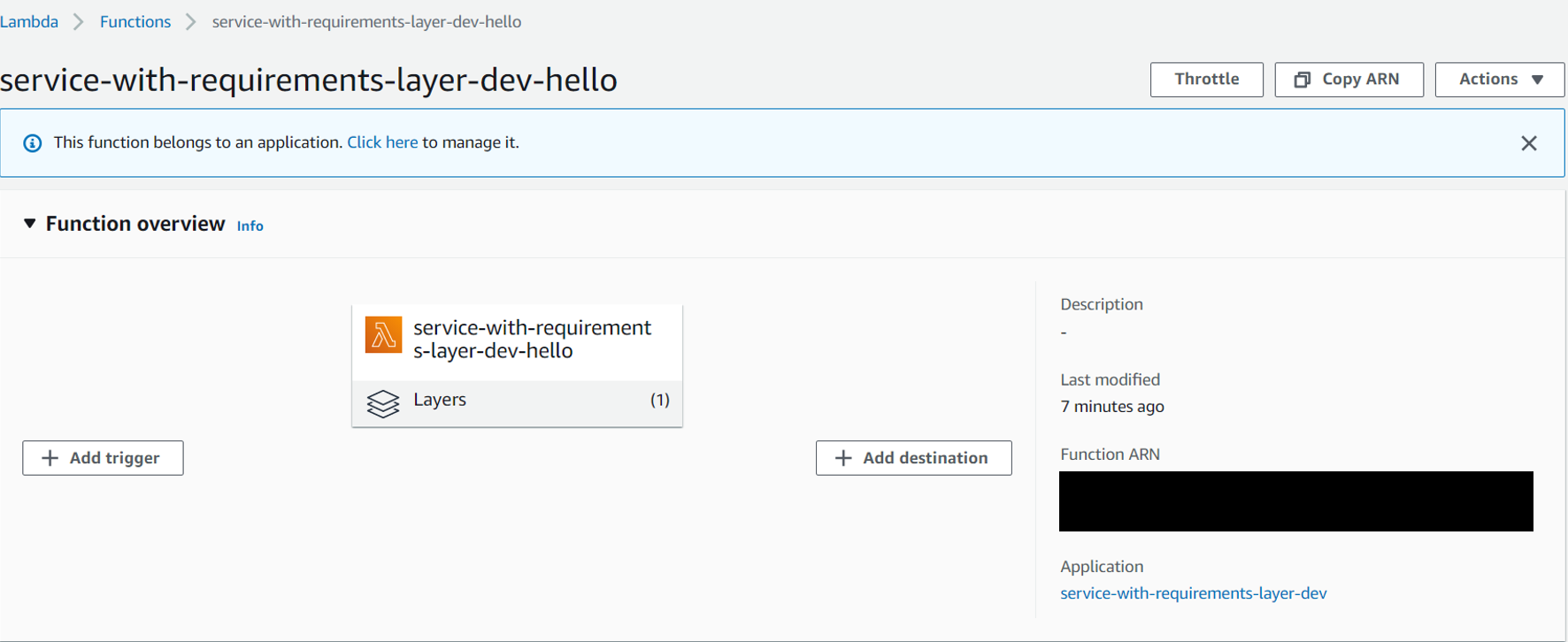
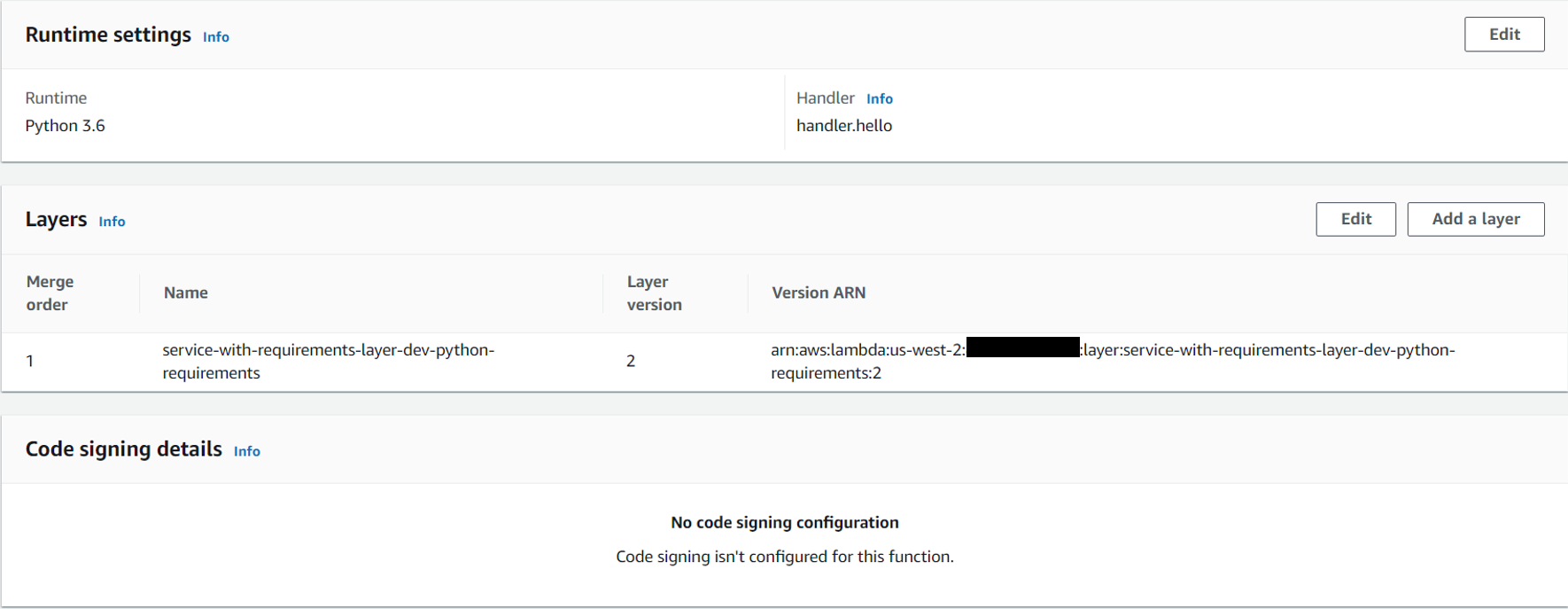
If you now click on the Layers button, you should be able to see the ARN of your layer. Note it down.
Deploy the second service, which uses the layer from the first service
Now, for this second service, we will not include a requirements.txt file. Nor will we add the serverless-python-requirements plugin. This is because we will be reusing the layer defined in the first service.
The serverless.yml file for this service is given below:
service: service-reusing-layer
provider:
name: aws
runtime: python3.6
lambdaHashingVersion: 20201221
region: us-west-2
functions:
hello:
handler: handler.hello
layers:
- arn:aws:lambda:us-west-2:XXXXXXXXXXXX:layer:service-with-requirements-layer-dev-python-requirements:2You can see that the hello function takes in the ARN of the layer obtained from the previous service. The handler hello function is given below:
import json
import numpy as np
def hello(event, context):
print(np.random.randint(5))
body = {
"message": "Go Serverless v1.0! Your function executed successfully!",
"input": event
}
response = {
"statusCode": 200,
"body": json.dumps(body)
}
return responseYou can see that it uses the numpy library to print a random integer less than 5. There is no requirements.txt here. We just hope that the layer deployed in the previous service, which contains numpy, will work here.
Deploy this function to AWS. When you check this function on AWS Console, you will see that it contains a layer.
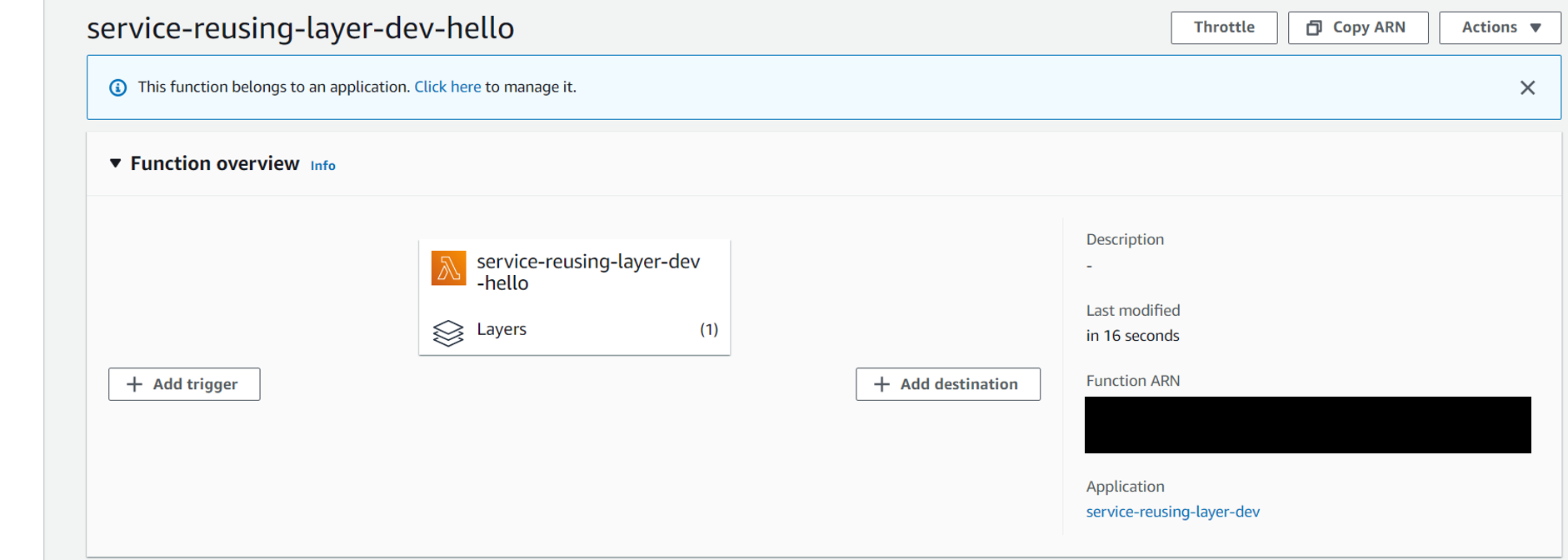
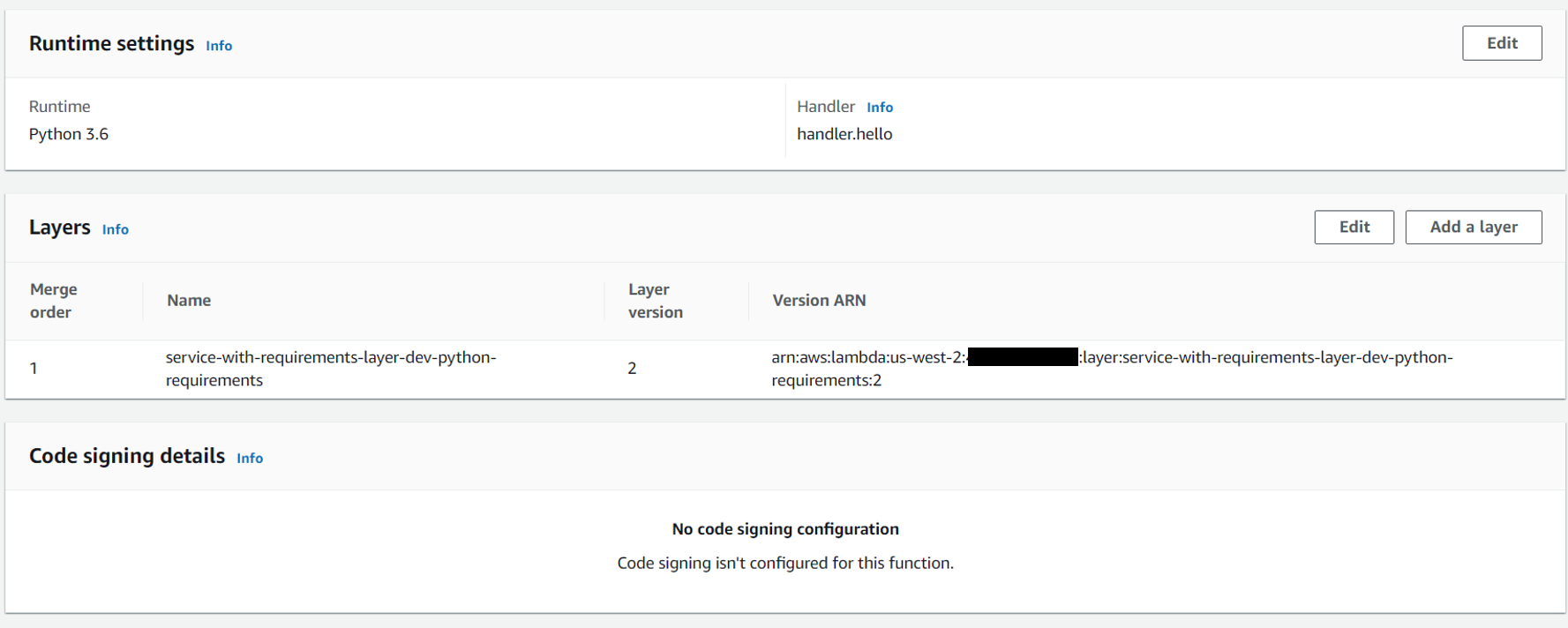
If you click on Layers, you will see that this is the same layer from the previous service.
Test out a function in the second service
Now, try invoking the function in AWS Console. It should work just fine and you should see a random integer less than 5, printed in the logs.
If you remove the layer from serverless.yml and then redeploy the function, and then invoke it, it will throw up the module not found error for NumPy. The exact statement of the error will be:
Unable to import module ‘handler’: No module named ‘numpy’
Thus, you can see how the requirements layer uploaded in one service can be reused within others quite seamlessly, using just the ARN of the layer. This holds true for all types of layers, not just the requirements layer.
Why share layers across services?
There are several reasons, even if we just consider the requirements layer and don’t generalize. The two major reasons are discussed below:
- Quicker deployment – The deployment size for the service reusing the layer was just 339 B (not even KB). Thus, it was deployed much faster. Of course, significant time was saved because of lack of docker container creation and packaging.
- Lesser storage occupied on S3 – If you have 100 different services, all utilizing almost the same libraries, then creating 100 different layers will add to the S3 cost
Closing Thoughts
This tutorial explains how layers can be reused across services. Please note that you can add a maximum of 5 layers to a lambda function. And the total size of your application code + layers should be less than 250 MB. Therefore, make sure that your layers are not too bulky.
Enjoyed this tutorial? Then have a look at other tutorials related to AWS here: https://iotespresso.com/category/aws/.
Also, if you are planning to become a certified AWS Solutions Architect, I’d recommend that you check out this course on Udemy. I took this course and found the lectures to be lucid, to-the-point, and fun.
1 comment